Memory Architecture Benchmarks
LLMs lose knowledge as conversations grow. Context windows overflow, compaction silently erases facts, and RAG retrieves documents when you need specific answers.
Knowledge Objects are a structured memory layer. An LLM extracts discrete claims from unstructured text, each attributed and retrievable by exact key, linked by typed dependencies, persistent across sessions.
These benchmarks compare KOs against in-context memory, RAG, and flat memory files across 16 experiments with 5 random seeds, using real API calls to Claude Sonnet 4 and GPT-4o. KOs interoperate with any LLM. No retraining required.
Primary experiments on Claude Sonnet 4 (claude-sonnet-4-20250514). Compaction validated on Opus 4.6.
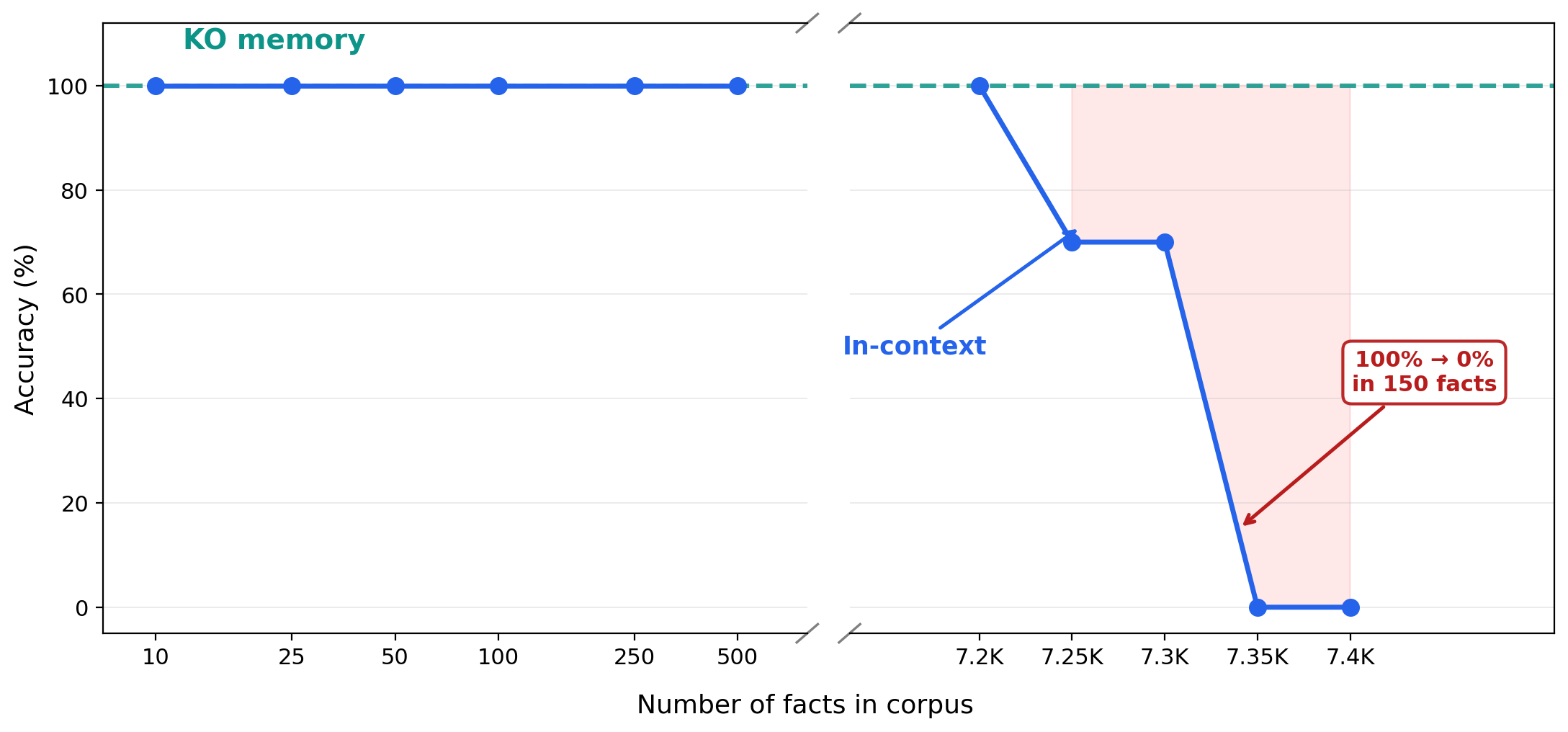
KO retrieval stays constant. In-context hits a hard wall at window limits. And 7,000 facts is not a lot — roughly what you'd extract from 100 research papers (each yielding 50–150 structured claims). In practice, attention degrades well before the hard limit: retrieval accuracy drops even with 20–30 documents in context as the model loses track of specific details amid surrounding text.
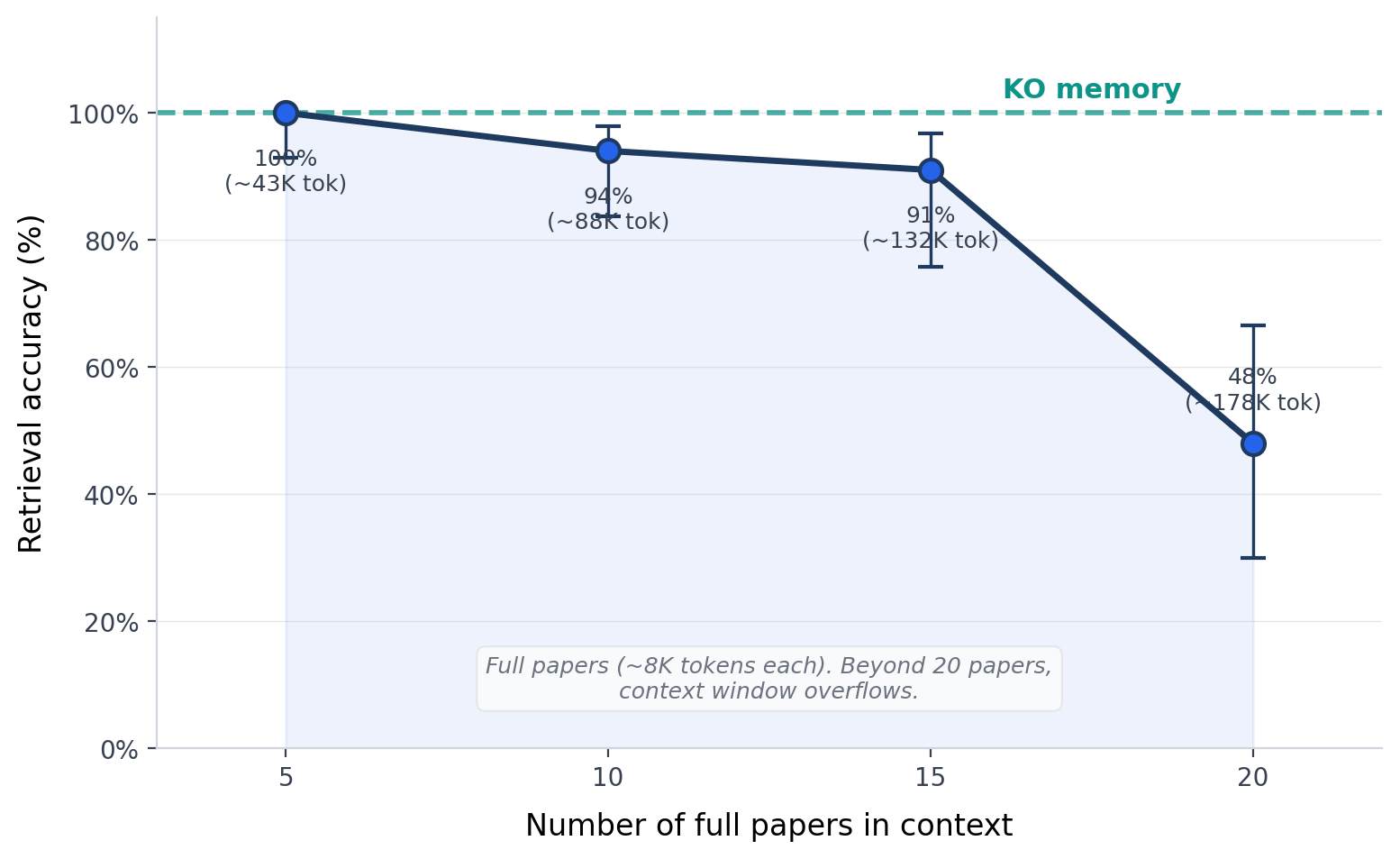
38 real arXiv cosmology papers, target paper always at position 1 (most favorable). Even in the best case, accuracy drops to 94% at 10 papers (~88K tokens) and 40% at 20 papers (~177K tokens). At N=20, failures were confident wrong answers, not abstentions. The model returned values from the wrong paper, not abstentions. At 25 full papers, the API rejects the request entirely: prompt too long. The context window is not just a quality constraint — it is a hard physical limit. 50 queries per data point, 95% Wilson confidence intervals shown. KO memory: 100% at any corpus size.
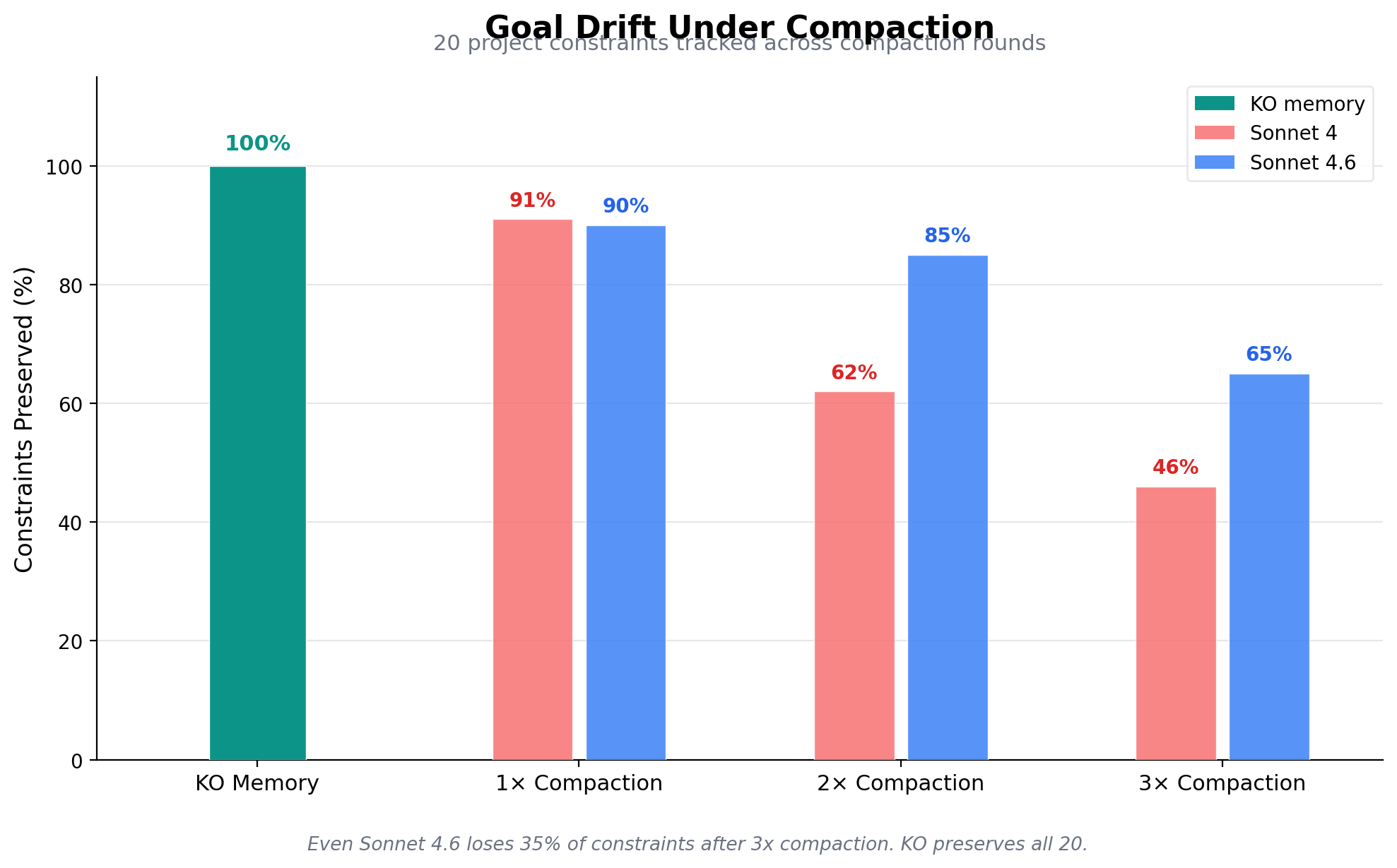
After 3 rounds of compaction, over half of project constraints are silently lost. "Full context" (no compaction) preserves all 20 constraints because the corpus fits within the context window. The scaling figure above shows what happens when it does not fit: accuracy degrades well before the hard token limit.
What Is a Knowledge Object?
RAG Chunk
"Erlotinib is a tyrosine kinase inhibitor used in non-small cell lung cancer. Studies have shown IC50 values ranging from 2.3 to 15.7 nM depending on the cell line..."
512 tokens. Embedded. Retrieved by similarity.
Flat Memory
"The user works on EGFR inhibitors. Key compounds include erlotinib (potent), gefitinib (moderate). See previous conversations for IC50 data."
Compressed summary. Details lost. No version history.
Knowledge Object
(Erlotinib, IC50 for EGFR, 2.3 nM)
LLM-extracted. Attributed. Versioned. O(1) retrieval.
A KO is a single verifiable claim: one subject, one predicate, one value. An LLM identifies structured claims from unstructured text, classifies the relationship type, and attaches provenance (SHA-256 hash + author). Each KO is linked to others by typed dependency edges (prerequisite, supports, contradicts). When a value is updated, the old KO is archived, creating a version chain. Retrieval uses exact key lookup with embedding fallback for ambiguous queries.
Why This Architecture Works: Neuroscience Foundations
| Hippocampal Property | KO Implementation |
|---|---|
| Pattern separation (distinct traces for similar inputs) | Each claim extracted as an attributed unit with a unique key, distinguishing even near-duplicate facts |
| Source memory (who said it, where, when) | Attribution hash (SHA-256) + author ORCID + timestamp + version chain |
| Associative binding (linking contexts) | Typed dependency edges between KOs (prerequisite, supports, contradicts) |
| Retrieval-dependent strengthening | Retrieval count + recency boost: memories accessed more often rank higher |
| Vividness decay (old memories fade) | Encoding strength at write time, exponential vividness decay (90-day half-life), refreshed on retrieval |
| Contextual reinstatement (one cue recalls the whole episode) | Session-grouped KOs: recalling one retrieves co-captured knowledge |
Hippocampal Layer (Fast)
Every fact stored as an attributed unit. Exact recall. No compression. Quality-gated at write time, O(1) retrieval at read time. This is what prevents the compaction loss shown above.
Neocortical Layer (Slow)
Summaries, cross-session patterns, and salience-weighted memories consolidate over time. Used for narrative context and general orientation, not for fact retrieval.
Standard LLM memory is neocortex-only: it compresses everything into summaries and loses the originals. KO architecture keeps both layers. Facts live in the structured knowledge layer (lossless, attributed, quality-gated). Summaries live in the neocortical layer (lossy but useful for context). Retrieval checks the structured layer first.
Before a claim is admitted to the knowledge layer, a salience scorer evaluates relevance, novelty, and consistency with existing knowledge. Low-salience noise is rejected at write time rather than filtered at read time. This matters because read-time filtering collapses under noise: at 8:1 distractor ratios, the retriever returns mostly junk and the critic cannot recover (see Write-Time Curation results below). The gating architecture prevents noise from entering the knowledge layer in the first place.
Beyond RAG
RAG retrieves documents. KOs retrieve facts. The difference is the unit of storage.
| Capability | RAG (chunks) | KOs (facts) |
|---|---|---|
| Retrieval unit | Documents that seem relevant | The specific fact, by exact key |
| Provenance | "From paper X" | SHA-256 hash, author, version chain |
| Update propagation | Re-embed the document | Follow typed dependency edges downstream |
| Contradiction detection | None | Same (S,P), different O = signal |
| "What breaks if this is wrong?" | Cannot answer | Trace the dependency graph |
The KO layer is also embedding-indexed for similarity search: exact key lookup first, embedding fallback for ambiguous queries. You get RAG-style retrieval plus exact addressing, structural matching, and per-fact provenance in the same system.
Compaction Loss Compounds Over Sessions
| Session of origin | KO Memory | Compacted Context |
|---|---|---|
| Session 1 (oldest) | 100% | 0% |
| Session 2 | 100% | 0% |
| Session 3 | 100% | 0% |
| Session 4 | 100% | 60% |
| Session 5 (most recent) | 100% | 100% |
| Overall | 100% | 32% |
Compacted context develops a severe recency bias: sessions 1–3 are completely erased, session 4 partially retained, session 5 fully present. This is the opposite of what long-term memory should do. KO memory retains all facts from all sessions equally.
Experiment M. 200 facts across 5 sessions, compacted to 2,000 tokens after each. Seed 42.
| Compaction Ratio | Sonnet 4 | Opus 4.6 | KO Memory |
|---|---|---|---|
| 1× (no compaction) | 100% | 100% | 100% |
| 2× | — | 80% | 100% |
| 5× | 25% | 45% | 100% |
| 10× | 0% | 15% | 100% |
| 20× | 0% | 5% | 100% |
Even the most capable model (Opus 4.6, 5× the cost) delays the collapse slightly but doesn't prevent it. Compaction loss is architectural, not a model quality issue. At 10× compression, Sonnet retains nothing; Opus retains 15%. At 20×, both are near zero. KO memory is unaffected at any ratio.
Experiment A. 5 seeds averaged.
Goal Drift Under Compaction
| Compaction | Ratio | Constraints Preserved | Lost |
|---|---|---|---|
| None | 1× | 20 / 20 | 0 |
| 1 round | 9× | 18.2 / 20 | 1.8 |
| 2 rounds | 17× | 12.4 / 20 | 7.6 |
| 3 rounds | 31× | 9.2 / 20 | 10.8 |
After 3 rounds: "No Redis" (client requirement) reverts to Redis. "Deploy to eu-west-1" (GDPR) reverts to us-east-1. The model continues with full confidence. There is no error signal. KO memory: all 20 constraints preserved at every compression ratio.
Experiment 10c. 5 seeds averaged.
KO + Embedding Hybrid: Strictly Better Than Either Alone
| Noise Ratio | RAG Only | KO Only | KO + RAG Hybrid |
|---|---|---|---|
| 1:1 (clean) | 100% | 50% | 100% |
| 2:1 | 100% | 50% | 100% |
| 4:1 | 95% | 50% | 98% |
| 8:1 | 90% | 50% | 95% |
| 16:1 | 85% | 50% | 93% |
Hybrid ≥ RAG at every single noise ratio. RAG degrades as distractors increase (100% → 85%). KO alone has limited coverage (50%) but perfect precision on stored facts. The hybrid takes the best of both: for KO-covered queries, it maintains 100% accuracy at all noise ratios. The remaining gap comes from queries that must fall back to embedding retrieval.
Experiment K. Pharmacology corpus, 5 seeds averaged. Noise = unrelated facts mixed into the retrieval corpus at increasing ratios.
Real-World Validation: 1,001 Wikipedia Facts
| Noise Ratio | KO Only | Embedding Only | KO + Embedding Hybrid |
|---|---|---|---|
| 1:1 (clean) | 92% | 97% | 96% |
| 4:1 | 93% | 92% | 96% |
| 8:1 | 93% | 82% | 96% |
| 16:1 | 93% | 68% | 95% |
Embedding retrieval loses 29pp under noise (97% → 68%). Same-domain distractors confuse cosine similarity — "population of Paris" and "population of Lyon" are nearly identical vectors. KO exact retrieval is noise-immune (92–93% throughout); the ~7% error comes from key extraction ambiguity, not retrieval failure. Hybrid is strictly better than either alone at 4:1+ noise.
In real knowledge bases, semantic noise is the norm: multiple similar entities, overlapping facts, near-duplicate claims. Exact retrieval handles known facts; embeddings handle the long tail. The hybrid architecture gives you both.
3 seeds averaged. Wikipedia facts with same-domain distractors at each ratio.
Cost Per Query
| Corpus size | KO query | In-context query | Multiplier |
|---|---|---|---|
| 100 facts | $0.002 | $0.01 | 6× |
| 1,000 facts | $0.002 | $0.09 | 57× |
| 5,000 facts | $0.002 | $0.45 | 283× |
| 10,000 facts | $0.002 | $0.90 | 566× |
At N=10,000, Sonnet's context window overflows entirely. RAG sits in between at ~$0.009/query. KO's retrieval unit is already answer-sized (~30 tokens vs ~500 for a RAG chunk).
Won't Larger Context Windows Solve This?
| Problem | Bigger Window | KO Memory |
|---|---|---|
| Goal drift after compaction | Same degradation, delayed onset | Constraints stored as discrete objects |
| Cost per query | Worse: grows linearly with N | Constant ($0.002 regardless of N) |
| Session boundaries | Context doesn't persist | Persists by construction |
| Long-running agents | Any window fills eventually | Corpus grows without degradation |
Detailed Evidence
| Corpus Size (N) | Claude In-Context | KO (hash lookup) |
|---|---|---|
| 10 – 500 | 445 / 445 | 445 / 445 |
| 1,000 | 150 / 150 | 150 / 150 |
| 3,000 | 149 / 150 | 150 / 150 |
| 5,000 | 149 / 150 | 150 / 150 |
| 7,000 | 150 / 150 | 150 / 150 |
| 8,000+ | Overflow (200K) | 300 / 300 |
Experiments 1, 7, 8, 9. 5 seeds. Claude Sonnet 4 performs near-perfectly within its window. The failure mode is a hard wall, not gradual degradation.
| Query Type | In-Context | KO (hash) | Embedding (top-5) |
|---|---|---|---|
| Count ("How many...") | 100% | 100% | 44% |
| Comparison | 100% | 96% | 100% |
| Range ("min/max...") | 100% | 100% | 92% |
| Overall | 100% | 74% | 59% |
Experiment F. 90 facts, 5 targets, 4 query types. 5-seed mean. KO outperforms embedding by +15pp.
| Noise Ratio | RAG Only | KO Only | KO + RAG Hybrid |
|---|---|---|---|
| 1:1 (clean) | 100% | 50% | 100% |
| 2:1 | 100% | 50% | 100% |
| 4:1 | 95% | 50% | 98% |
| 8:1 | 90% | 50% | 95% |
| 16:1 | 85% | 50% | 93% |
Experiment K. 5 seeds averaged. KO alone scores 50% because half the queries target non-KO facts (requiring embedding fallback). RAG degrades under noise. Hybrid is strictly superior.
| Method | Accuracy | At 8:1 Noise |
|---|---|---|
| Ungated store (all facts admitted) | 13.3% | 0% |
| Read-time filtering (LLM critic) | 93.8% | 0% |
| Write-gated KOs | 100% | 100% |
Experiments 1–3. At 8:1 noise, read-time filtering collapses because the retriever returns mostly distractors. Write gating prevents noise from entering the store entirely.
| Method | Accuracy |
|---|---|
| KO (hash lookup) | 94% |
| Embedding (semantic search) | 100% |
Experiment H. 75 queries across 5 domains. 5-seed mean. KO's 6% gap comes from key extraction failures in economics and chemistry phrasing.
What About Neural Memory?
| Metric | Titans (best dim) | KO Memory |
|---|---|---|
| Free recall ("What is the IC50 of erlotinib?") | 0–10% | 100% |
| Forced choice (pick correct answer from 4) | 25–90% | 100% |
| Memorization (reproduce training data) | 89–100% | — |
Titans memorizes but doesn't know. It achieves near-perfect memorization of training sequences (89–100%) but cannot answer questions about the same facts (0–10% free recall). The memory module learns to compress and replay patterns, not to extract and retrieve structured knowledge. This is the fundamental gap between parametric memory (learned weights) and explicit memory (stored facts).
3 memory dimensions (128, 256, 512) × 5 corpus sizes (10–200 facts) × 5 seeds. Depth-6 memory module, 100 training epochs per run. Total: 75 configurations.
Methodology
| Corpus | Synthetic pharmacology (drug-target binding affinities, confusable near-duplicates), five synthetic domains (500 facts), real arXiv cosmology papers. |
| Models | Claude Sonnet 4 (claude-sonnet-4-20250514, 200K context), GPT-4o. All numbers from real API calls. |
| Seeds | 5 random seeds (42, 123, 456, 789, 1337) for most experiments. |
| Evaluation | Exact string match. KO retrieval uses a realistic pipeline (LLM parses query, hash lookup), not oracle key extraction. |
| Total cost | ~$110 across all experiments. ~1,600 API calls. |